库 | qlib基于法学硕士的工业数据驱动研发自主进化代理

Qlib是一个面向人工智能的量化投资平台,旨在利用人工智能技术赋能量化研究,从探索想法到实现产品。 Qlib 支持多种 ML 建模范例,包括监督学习、市场动态建模和 RL,现在配备了 https://github.com/microsoft/RD-Agent 来自动化研发过程。

📰 什么是新的! :闪闪发光的心:
最近发布的功能
Introducing  :基于法学硕士的工业数据驱动研发自主进化代理
:基于法学硕士的工业数据驱动研发自主进化代理
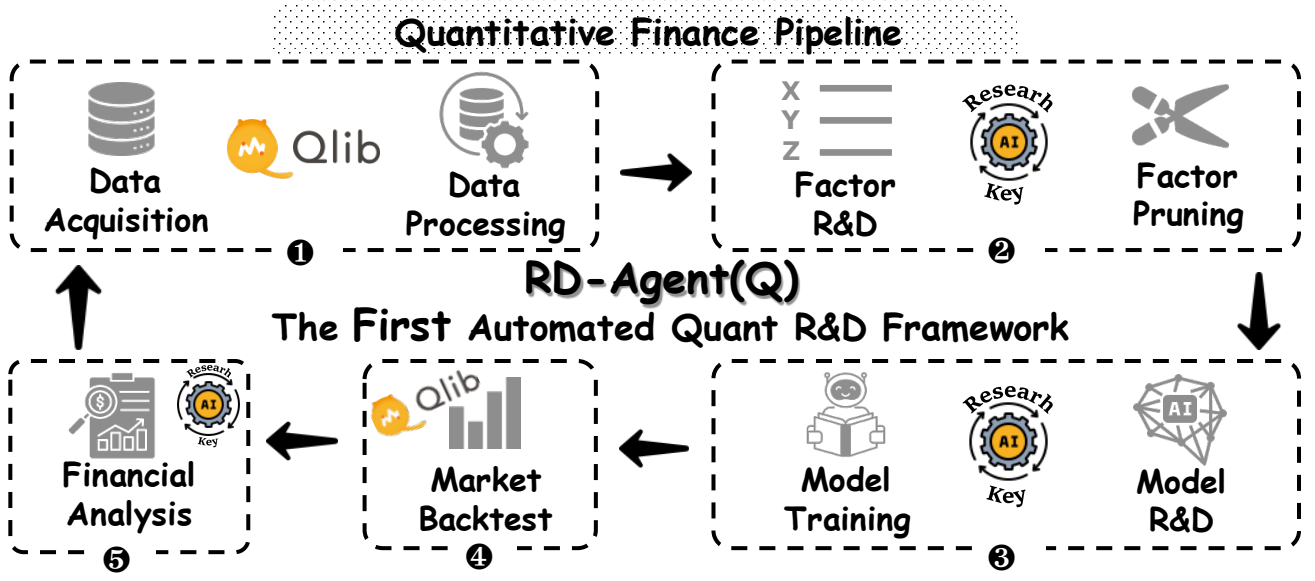
我们很高兴地宣布发布RD-Agent📢,支持量化投资研发中自动化因子挖掘和模型优化的强大工具。
RD-Agent 现已推出GitHub,我们欢迎您的明星🌟!
要了解更多信息,请访问我们的♾️演示页面。在这里,您可以找到中英文演示视频,帮助您更好地了解RD-Agent的场景和使用。
我们为您准备了几个演示视频:
| Scenario | 演示视频(英文) | Demo video (中文) |
|---|---|---|
| 量化因子挖掘 | Link | Link |
| 从报告中挖掘量化因素 | Link | Link |
| 定量模型优化 | Link | Link |
- 📃Paper: R&D-Agent-Quant:用于以数据为中心的因素和模型联合优化的多代理框架
- 👾Code: https://github.com/microsoft/RD-Agent/
@misc{li2025rdagentquant,
title={R\&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization},
author={Yuante Li and Xu Yang and Xiao Yang and Minrui Xu and Xisen Wang and Weiqing Liu and Jiang Bian},
year={2025},
eprint={2505.15155},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
| Feature | Status |
|---|---|
| 研发-代理-定量 Published | 将R&D-Agent应用到Qlib进行量化交易 |
| 用于端到端学习的 BPQP | 📈即将推出!(审核中) |
| 🔥LLM驱动的汽车定量工厂🔥 | 🚀 发布于♾️RD-代理2024 年 8 月 8 日 |
| KRNN 和三明治模型 | 📈 Released于 2023 年 5 月 26 日 |
| 发布 Qlib v0.9.0 | :八猫:Released2022 年 12 月 9 日 |
| 强化学习学习框架 | 🔨 📈 于 2022 年 11 月 10 日发布。#1332, #1322, #1316,#1299,#1263, #1244, #1169, #1125, #1076 |
| HIST 和 IGMTF 模型 | 📈 Released2022 年 4 月 10 日 |
| Qlib 笔记本教程 | 📖 Released2022 年 4 月 7 日 |
| 伊博维斯帕指数数据 | :米:Released2022 年 4 月 6 日 |
| 时间点数据库 | 🔨 Released2022 年 3 月 10 日 |
| Arctic 提供商后端和订单簿数据示例 | 🔨 Released2022 年 1 月 17 日 |
| 基于元学习的框架和 DDG-DA | 📈 🔨 Released2022 年 1 月 10 日 |
| 基于规划的投资组合优化 | 🔨 Released2021 年 12 月 28 日 |
| 发布 Qlib v0.8.0 | :八猫:Released2021 年 12 月 8 日 |
| 添加模型 | 📈 Released于 2021 年 11 月 22 日 |
| ADARNN模型 | 📈 Released2021 年 11 月 14 日 |
| TCN模型 | 📈 Released2021 年 11 月 4 日 |
| 嵌套决策框架 | 🔨 Released2021 年 10 月 1 日。Example and Doc |
| 时间路由适配器 (TRA) | 📈 Released2021 年 7 月 30 日 |
| 变压器和本地变压器 | 📈 Released于 2021 年 7 月 22 日 |
| 发布 Qlib v0.7.0 | :八猫:Released2021 年 7 月 12 日 |
| TCTS模型 | 📈 Released2021 年 7 月 1 日 |
| 在线服务和自动模型滚动 | 🔨 Released于 2021 年 5 月 17 日 |
| 双系综模型 | 📈 Released2021 年 3 月 2 日 |
| 高频数据处理示例 | 🔨 Released于 2021 年 2 月 5 日 |
| 高频交易示例 | 📈 部分代码发布2021 年 1 月 28 日 |
| 高频数据(1分钟) | :米:Released2021 年 1 月 27 日 |
| 平板电脑型号 | 📈 Released2021 年 1 月 22 日 |

Qlib是一个开源的、面向人工智能的量化投资平台,旨在利用人工智能技术在量化投资中从探索想法到落地产品,发挥潜力、赋能研究、创造价值。 Qlib 支持多种机器学习建模范例,包括监督学习、市场动态建模和强化学习。
Qlib 正在发布越来越多不同范式的 SOTA Quant 研究著作/论文,以协作解决量化投资的关键挑战。例如,1)使用监督学习从丰富且异构的金融数据中挖掘市场复杂的非线性模式,2)使用自适应概念漂移技术对金融市场的动态性质进行建模,以及3)使用强化学习对持续投资决策进行建模并协助投资者优化其交易策略。
它包含数据处理、模型训练、回测的完整机器学习流程;涵盖量化投资的整个链条:阿尔法寻求、风险建模、投资组合优化和订单执行。
欲了解更多详情,请参阅我们的论文《Qlib:面向人工智能的量化投资平台》.
| 框架、教程、数据和 DevOps | 定量研究的主要挑战和解决方案 |
|---|---|
|
|
|
Plans
New features under development(order by estimated release time). Your feedbacks about the features are very important.Qlib框架
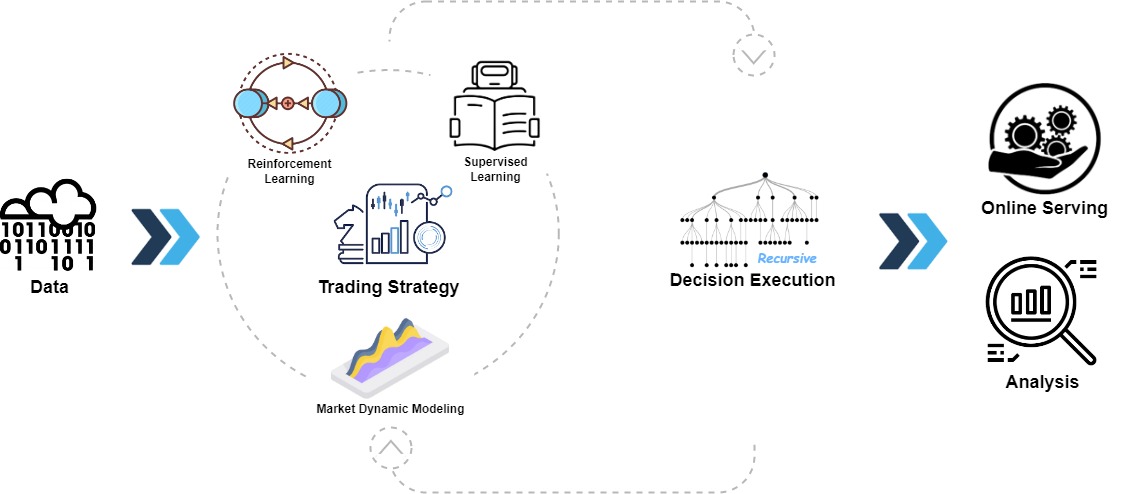
Qlib的高层框架可以在上面找到(用户可以找到详细框架深入了解 Qlib 设计的本质)。
这些组件被设计为松耦合模块,每个组件都可以独立使用。
Qlib 提供了强大的基础设施来支持定量研究。Data始终是重要的一部分。
强大的学习框架旨在支持多样化的学习范式(例如强化学习, 监督学习)和不同级别的模式(例如市场动态建模).
通过对市场进行建模,交易策略将生成将被执行的贸易决策。不同级别或粒度的多种交易策略和执行器可以嵌套优化并一起运行.
最后来一个全面的analysis将提供并且模型可以是在线服务以低成本。
快速入门
本快速入门指南试图演示
- 构建完整的定量研究工作流程并尝试您的想法非常容易Qlib.
- 虽然与公开数据 and 简单模型、机器学习技术工作得很好在实际的量化投资中。
这是一个快速demo shows how to install `
Qlib, and run LightGBM with qrun. But, please make sure you have already prepared the data following the instruction.
Installation
This table demonstrates the supported Python version of
Qlib:
install with pip install from source plot Python 3.8 ✅ ✅ ✅ Python 3.9 ✅ ✅ ✅ Python 3.10 ✅ ✅ ✅ Python 3.11 ✅ ✅ ✅ Python 3.12 ✅ ✅ ✅
Note:
- Conda is suggested for managing your Python environment. In some cases, using Python outside of a
conda environment may result in missing header files, causing the installation failure of certain packages.Please pay attention that installing cython in Python 3.6 will raise some error when installing Qlib from source. If users use Python 3.6 on their machines, it is recommended to upgrade Python to version 3.8 or higher, or use conda's Python to install Qlib from source.
Install with pip
Users can easily install Qlib by pip according to the following command.
pip install pyqlib
Note:pip 将安装最新的稳定 qlib。然而,qlib 的主要分支正在积极开发中。如果你想测试主分支中最新的脚本或函数。请使用以下方法安装qlib。从源安装
此外,用户可以安装最新的开发版本Qlib by the source code according to the following steps:
- Before installing
Qlib from source, users need to install some dependencies:
pip install numpy
pip install --upgrade cython
- 克隆存储库并安装
Qlib as follows. git clone https://github.com/microsoft/qlib.git && cd qlib
pip install . # `pip install -e .[dev]` is recommended for development. check details in docs/developer/code_standard_and_dev_guide.rst
Tips: 如果安装失败Qlib or run the examples in your environment, comparing your steps and the CI workflow may help you find the problem.
Tips for Mac: If you are using Mac with M1, you might encounter issues in building the wheel for LightGBM, which is due to missing dependencies from OpenMP. To solve the problem, install openmp first with brew install libomp and then run pip install . to build it successfully.
Data Preparation
❗ Due to more restrict data security policy. The official dataset is disabled temporarily. You can try this data source contributed by the community.
Here is an example to download the latest data.
wget https://github.com/chenditc/investment_data/releases/latest/download/qlib_bin.tar.gz
mkdir -p ~/.qlib/qlib_data/cn_data
tar -zxvf qlib_bin.tar.gz -C ~/.qlib/qlib_data/cn_data --strip-components=1
rm -f qlib_bin.tar.gz
下面的官方数据集将在不久的将来恢复。
通过运行以下代码加载并准备数据:通过模块获取
# get 1d data
python -m qlib.cli.data qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.cli.data qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min
从源头获取
# get 1d data
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# get 1min data
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min
该数据集是由以下机构收集的公共数据创建的爬虫脚本,已发布于
相同的存储库。
用户可以用它创建相同的数据集。数据集描述
*请付款ATTENTION数据收集自雅虎财经,而且数据可能并不完美。
如果用户拥有高质量的数据集,我们建议他们准备自己的数据。欲了解更多信息,用户可以参考相关文件*.
自动更新每日频率数据(来自雅虎财经)
>这一步是Optional if users only want to try their models and strategies on history data.
>
> It is recommended that users update the data manually once (--trading_date 2021-05-25) and then set it to update automatically.
>
> NOTE:用户无法基于Qlib提供的离线数据增量更新数据(为了减少数据大小,删除了一些字段)。用户应该使用雅虎收藏家 to download Yahoo data from scratch and then incrementally update it.
>
>更多信息请参考:雅虎收藏家
* 每个交易日自动更新数据到“qlib”目录(Linux)
use 定时任务*:
crontab -e
* set up timed tasks:
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
脚本路径: 脚本/data_collector/yahoo/collector.py** 手动更新数据
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
Trading_date*:交易日开始
end_date*: 交易日结束(不包括在内)
检查数据的健康状况
* We provide a script to check the health of the data, you can run the following commands to check whether the data is healthy or not.
python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data
* Of course, you can also add some parameters to adjust the test results, such as this.
python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data --missing_data_num 30055 --large_step_threshold_volume 94485 --large_step_threshold_price 20
* If you want more information about , please refer to the documentation.
Docker 镜像
- 从 docker hub 存储库中提取 docker 镜像
docker pull pyqlib/qlib_image_stable:stable
- 启动一个新的 Docker 容器
docker run -it --name <container name> -v <Mounted local directory>:/app pyqlib/qlib_image_stable:stable
- 此时您已处于 docker 环境中并且可以运行 qlib 脚本。一个例子:
>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~/.qlib/qlib_data/cn_data --interval 1d --region cn
>>> python qlib/cli/run.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
- 退出容器
>>> exit
- 重启容器
docker start -i -a <container name>
- 停止容器
docker stop <container name>
- 删除容器
docker rm <container name>
- 如果您想了解更多信息,请参阅documentation.
自动定量研究工作流程
Qlib 提供了一个名为qrun to run the whole workflow automatically (including building dataset, training models, backtest and evaluation). You can start an auto quant research workflow and have a graphical reports analysis according to the following steps:
- Quant Research Workflow: Run
qrun with lightgbm workflow config (workflow_config_lightgbm_Alpha158.yaml as following. cd examples # Avoid running program under the directory contains `qlib`
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
如果用户想使用qrun under debug mode, please use the following command:
python -m pdb qlib/cli/run.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
结果qrun is as follows, please refer to docs for more explanations about the result.
'The following are analysis results of the excess return without cost.'
risk
mean 0.000708
std 0.005626
annualized_return 0.178316
information_ratio 1.996555
max_drawdown -0.081806
'The following are analysis results of the excess return with cost.'
risk
mean 0.000512
std 0.005626
annualized_return 0.128982
information_ratio 1.444287
max_drawdown -0.091078
这里有详细的文档qrun and workflow.
- Graphical Reports Analysis: First, run
python -m pip install .[analysis] to install the required dependencies. Then run examples/workflow_by_code.ipynb with jupyter notebook to get graphical reports. - Forecasting signal (model prediction) analysis
- Cumulative Return of groups
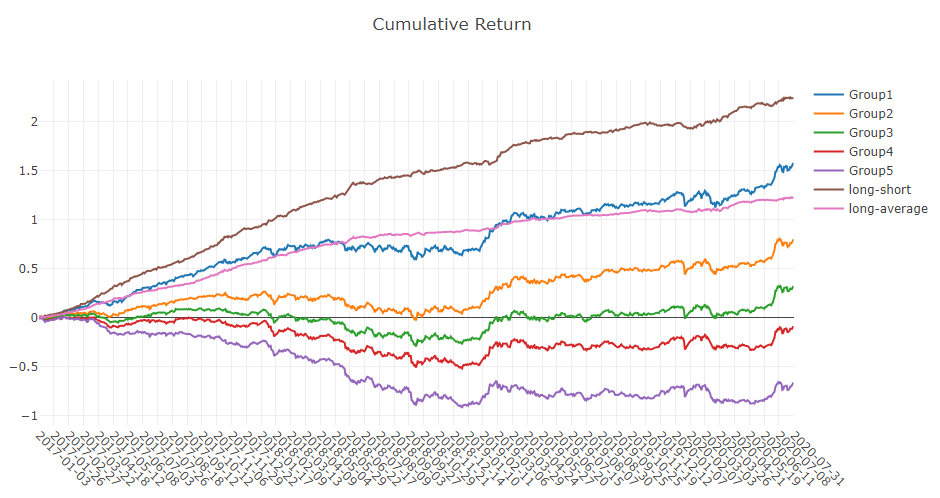 - Return distribution
- Return distribution
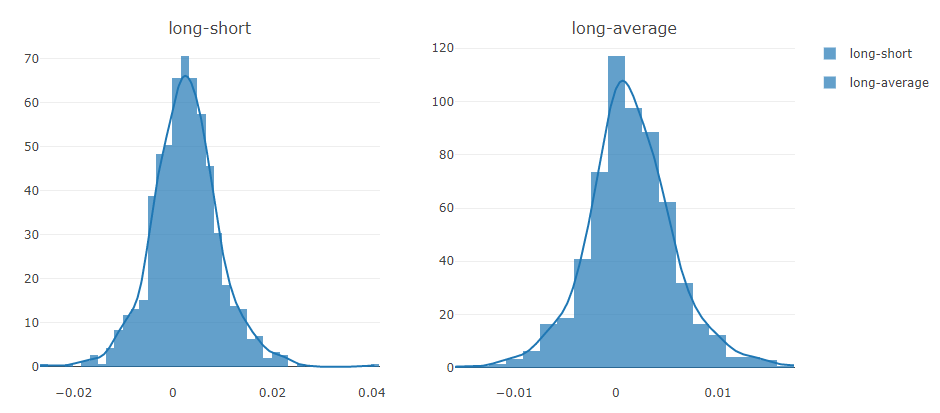 - Information Coefficient (IC)
- Information Coefficient (IC)
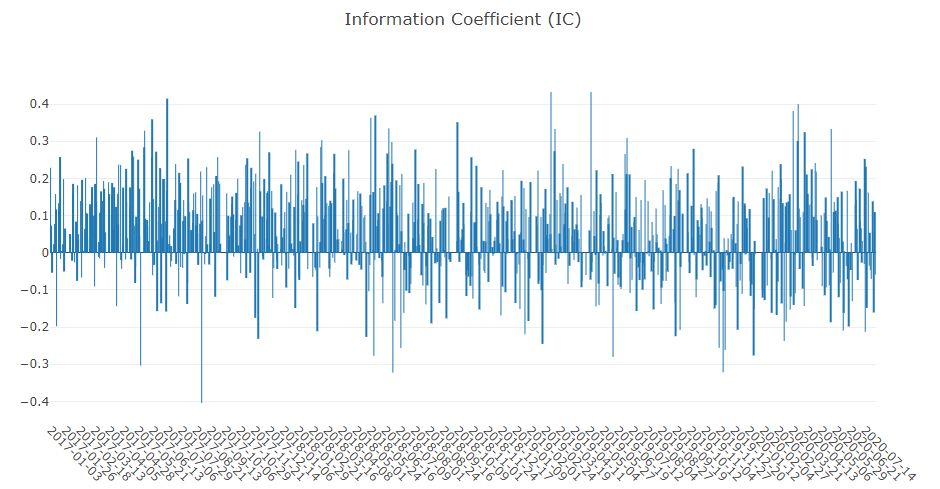
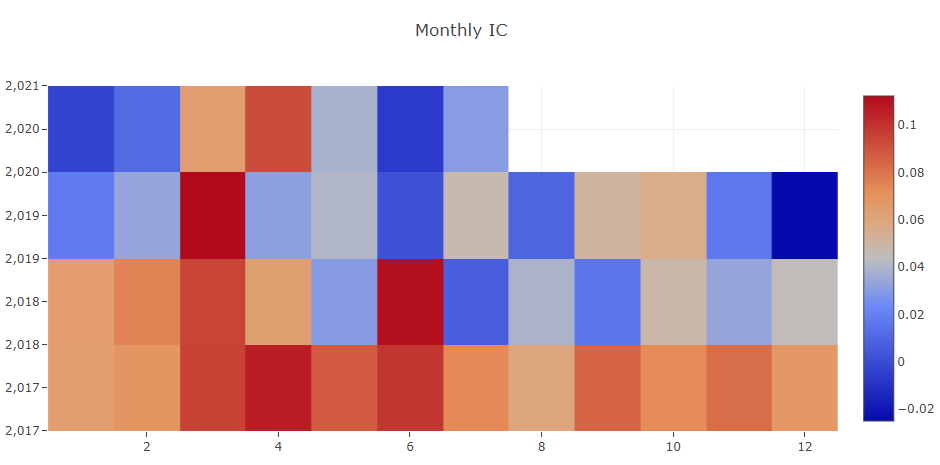
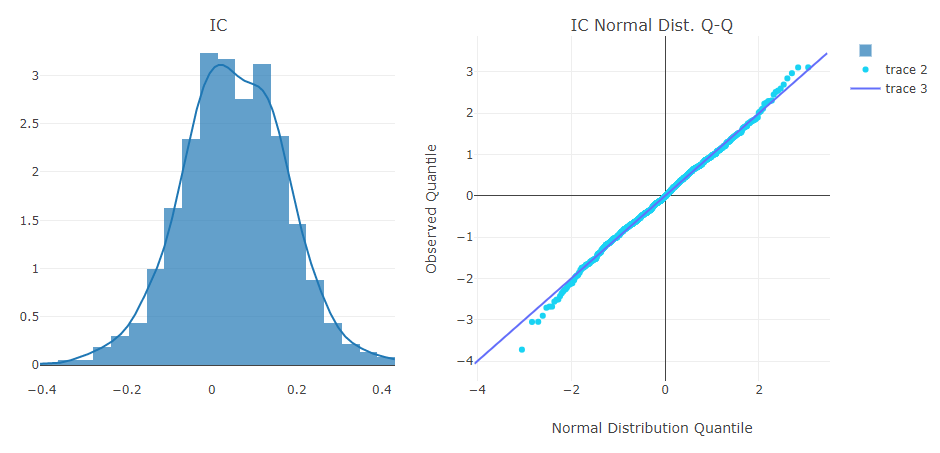 - Auto Correlation of forecasting signal (model prediction)
- Auto Correlation of forecasting signal (model prediction)
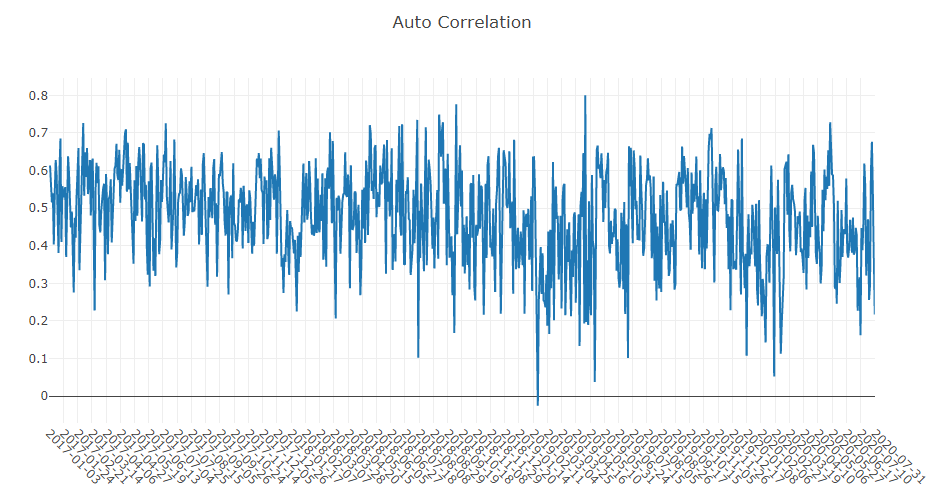
- Portfolio analysis
- Backtest return
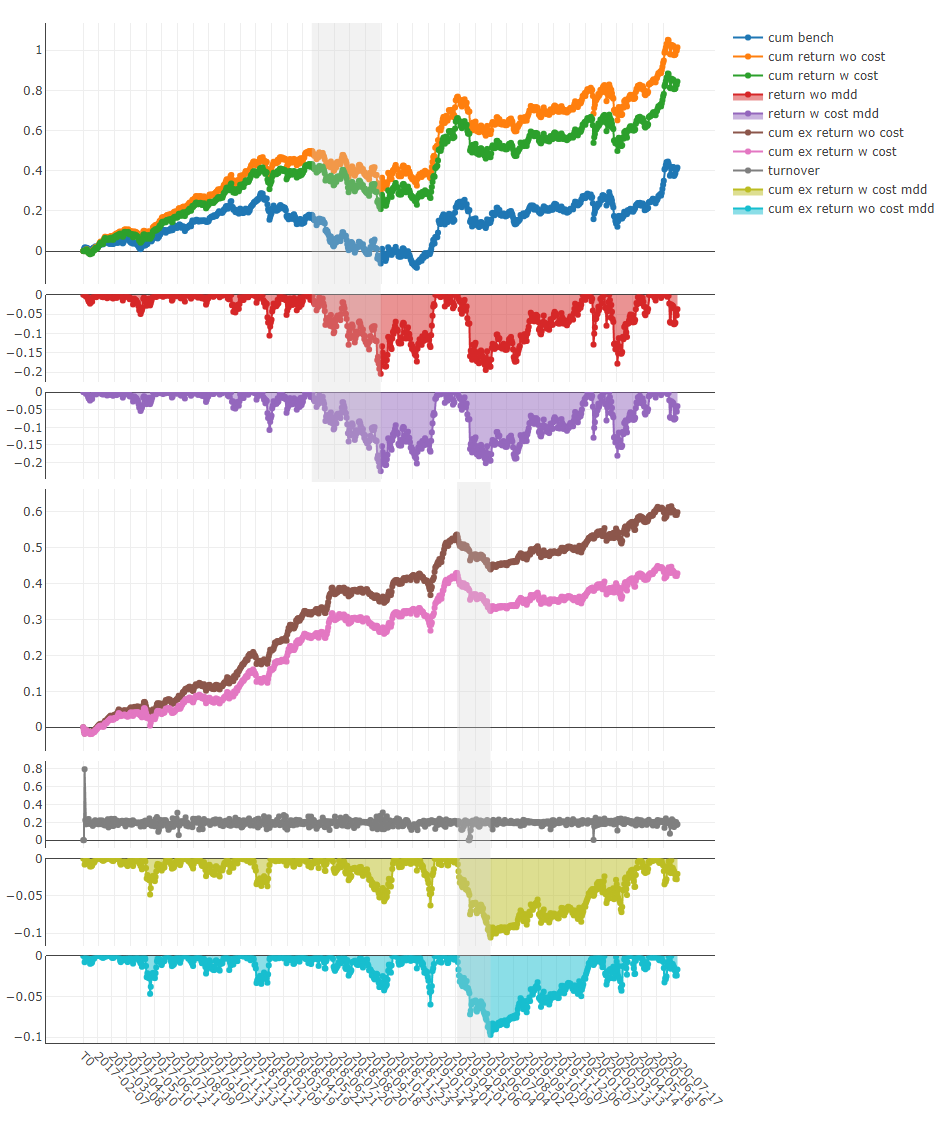
- Explanation of above results
Building Customized Quant Research Workflow by Code
The automatic workflow may not suit the research workflow of all Quant researchers. To support a flexible Quant research workflow, Qlib also provides a modularized interface to allow researchers to build their own workflow by code. Here is a demo for customized Quant research workflow by code.
Main Challenges & Solutions in Quant Research
Quant investment is a very unique scenario with lots of key challenges to be solved.
Currently, Qlib provides some solutions for several of them.
Forecasting: Finding Valuable Signals/Patterns
Accurate forecasting of the stock price trend is a very important part to construct profitable portfolios.
However, huge amount of data with various formats in the financial market which make it challenging to build forecasting models.
An increasing number of SOTA Quant research works/papers, which focus on building forecasting models to mine valuable signals/patterns in complex financial data, are released in
Qlib
Quant Model (Paper) Zoo
Here is a list of models built on
Qlib.
- GBDT based on XGBoost (Tianqi Chen, et al. KDD 2016)
- GBDT based on LightGBM (Guolin Ke, et al. NIPS 2017)
- GBDT based on Catboost (Liudmila Prokhorenkova, et al. NIPS 2018)
- MLP based on pytorch
- LSTM based on pytorch (Sepp Hochreiter, et al. Neural computation 1997)
- GRU based on pytorch (Kyunghyun Cho, et al. 2014)
- ALSTM based on pytorch (Yao Qin, et al. IJCAI 2017)
- GATs based on pytorch (Petar Velickovic, et al. 2017)
- SFM based on pytorch (Liheng Zhang, et al. KDD 2017)
- TFT based on tensorflow (Bryan Lim, et al. International Journal of Forecasting 2019)
- TabNet based on pytorch (Sercan O. Arik, et al. AAAI 2019)
- DoubleEnsemble based on LightGBM (Chuheng Zhang, et al. ICDM 2020)
- TCTS based on pytorch (Xueqing Wu, et al. ICML 2021)
- Transformer based on pytorch (Ashish Vaswani, et al. NeurIPS 2017)
- Localformer based on pytorch (Juyong Jiang, et al.)
- TRA based on pytorch (Hengxu, Dong, et al. KDD 2021)
- TCN based on pytorch (Shaojie Bai, et al. 2018)
- ADARNN based on pytorch (YunTao Du, et al. 2021)
- ADD based on pytorch (Hongshun Tang, et al.2020)
- IGMTF based on pytorch (Wentao Xu, et al.2021)
- HIST based on pytorch (Wentao Xu, et al.2021)
- KRNN based on pytorch
- Sandwich based on pytorch
Your PR of new Quant models is highly welcomed.
The performance of each model on the
Alpha158 and Alpha360 datasets can be found here.
Run a single model
All the models listed above are runnable with Qlib. Users can find the config files we provide and some details about the model through the benchmarks folder. More information can be retrieved at the model files listed above.
Qlib provides three different ways to run a single model, users can pick the one that fits their cases best:
- Users can use the tool
qrun mentioned above to run a model's workflow based from a config file.Users can create a workflow_by_code python script based on the one listed in the examples folder.
run_all_model.py listed in the examples folder to run a model. Here is an example of the specific shell command to be used: python run_all_model.py run --models=lightgbm, where the --models arguments can take any number of models listed above(the available models can be found in benchmarks). For more use cases, please refer to the file's docstrings. - NOTE: Each baseline has different environment dependencies, please make sure that your python version aligns with the requirements(e.g. TFT only supports Python 3.6~3.7 due to the limitation of tensorflow==1.15.0)
Run multiple models
Qlib also provides a script run_all_model.py which can run multiple models for several iterations. (Note: the script only support Linux for now. Other OS will be supported in the future. Besides, it doesn't support parallel running the same model for multiple times as well, and this will be fixed in the future development too.)
The script will create a unique virtual environment for each model, and delete the environments after training. Thus, only experiment results such as
IC and backtest results will be generated and stored.
Here is an example of running all the models for 10 iterations:
python run_all_model.py run 10
它还提供 API 来立即运行特定模型。有关更多用例,请参阅该文件的docstrings.
中断变更
In pandas, group_key is one of the parameters of the groupby method. From version 1.5 to 2.0 of pandas, the default value of group_key has been changed from no default to True, which will cause qlib to report an error during operation. So we set group_key=False, but it doesn't guarantee that some programmes will run correctly, including:
- qlib\examples\rl_order_execution\scripts\gen_training_orders.py
- qlib\examples\benchmarks\TRA\src\dataset.MTSDatasetH.py
- qlib\examples\benchmarks\TFT\tft.py
Adapting to Market Dynamics
Due to the non-stationary nature of the environment of the financial market, the data distribution may change in different periods, which makes the performance of models build on training data decays in the future test data.
So adapting the forecasting models/strategies to market dynamics is very important to the model/strategies' performance.
Here is a list of solutions built on
Qlib.
Reinforcement Learning: modeling continuous decisions
Qlib now supports reinforcement learning, a feature designed to model continuous investment decisions. This functionality assists investors in optimizing their trading strategies by learning from interactions with the environment to maximize some notion of cumulative reward.
Here is a list of solutions built on
Qlib categorized by scenarios.
RL for order execution
Here is the introduction of this scenario. All the methods below are compared here.
- TWAP
- PPO: "An End-to-End Optimal Trade Execution Framework based on Proximal Policy Optimization", IJCAL 2020
- OPDS: "Universal Trading for Order Execution with Oracle Policy Distillation", AAAI 2021
Quant Dataset Zoo
Dataset plays a very important role in Quant. Here is a list of the datasets built on Qlib:
Dataset US Market China Market Alpha360 √ √ Alpha158 √ √
Here is a tutorial to build dataset with Qlib.
Your PR to build new Quant dataset is highly welcomed.
Learning Framework
Qlib is high customizable and a lot of its components are learnable.
The learnable components are instances of Forecast Model and Trading Agent. They are learned based on the Learning Framework layer and then applied to multiple scenarios in Workflow layer.
The learning framework leverages the Workflow layer as well(e.g. sharing Information Extractor, creating environments based on Execution Env).
Based on learning paradigms, they can be categorized into reinforcement learning and supervised learning.
Execution Env in Workflow layer to create environments. It's worth noting that NestedExecutor is supported as well. This empowers users to optimize different level of strategies/models/agents together (e.g. optimizing an order execution strategy for a specific portfolio management strategy).
More About Qlib
If you want to have a quick glance at the most frequently used components of qlib, you can try notebooks here.
The detailed documents are organized in docs.
Sphinx and the readthedocs theme is required to build the documentation in html formats.
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make html
您还可以查看最新文件直接上网。
Qlib 正在积极持续的开发中。我们的计划包含在路线图中,该路线图作为github项目.
离线模式和在线模式
Qlib 的数据服务器可以部署为Offline mode or Online mode. The default mode is offline mode.
Under
Offline mode, the data will be deployed locally.
Under
Online mode, the data will be deployed as a shared data service. The data and their cache will be shared by all the clients. The data retrieval performance is expected to be improved due to a higher rate of cache hits. It will consume less disk space, too. The documents of the online mode can be found in Qlib-Server. The online mode can be deployed automatically with Azure CLI based scripts. The source code of online data server can be found in Qlib-Server repository.
Performance of Qlib Data Server
The performance of data processing is important to data-driven methods like AI technologies. As an AI-oriented platform, Qlib provides a solution for data storage and data processing. To demonstrate the performance of Qlib data server, we
compare it with several other data storage solutions.
We evaluate the performance of several storage solutions by finishing the same task,
which creates a dataset (14 features/factors) from the basic OHLCV daily data of a stock market (800 stocks each day from 2007 to 2020). The task involves data queries and processing.
HDF5 MySQL MongoDB InfluxDB Qlib -E -D Qlib +E -D Qlib +E +D Total (1CPU) (seconds) 184.4±3.7 365.3±7.5 253.6±6.7 368.2±3.6 147.0±8.8 47.6±1.0 7.4±0.3 Total (64CPU) (seconds) 8.8±0.6 4.2±0.2
* +(-)E indicates with (out) ExpressionCache
+(-)D indicates with (out) DatasetCache
Most general-purpose databases take too much time to load data. After looking into the underlying implementation, we find that data go through too many layers of interfaces and unnecessary format transformations in general-purpose database solutions.
Such overheads greatly slow down the data loading process.
Qlib data are stored in a compact format, which is efficient to be combined into arrays for scientific computation.
Related Reports
Contact Us
Qlib, please create pull requests.For other reasons, you are welcome to contact us by email(qlib@microsoft.com). - We are recruiting new members(both FTEs and interns), your resumes are welcome!
Join IM discussion groups:
Gitter 
Contributing
We appreciate all contributions and thank all the contributors!
Before we released Qlib as an open-source project on Github in Sep 2020, Qlib is an internal project in our group. Unfortunately, the internal commit history is not kept. A lot of members in our group have also contributed a lot to Qlib, which includes Ruihua Wang, Yinda Zhang, Haisu Yu, Shuyu Wang, Bochen Pang, and Dong Zhou. Especially thanks to Dong Zhou due to his initial version of Qlib.
Guidance
This project welcomes contributions and suggestions.
**Here are some
code standards and development guidance for submiting a pull request.**
Making contributions is not a hard thing. Solving an issue(maybe just answering a question raised in issues list or gitter), fixing/issuing a bug, improving the documents and even fixing a typo are important contributions to Qlib.
For example, if you want to contribute to Qlib's document/code, you can follow the steps in the figure below.

If you don't know how to start to contribute, you can refer to the following examples.
Type Examples Solving issues Answer a question; issuing or fixing a bug Docs Improve docs quality ; Fix a typo Feature Implement a requested feature like this; Refactor interfaces Dataset Add a dataset Models Implement a new model, some instructions to contribute models
Good first issues are labelled to indicate that they are easy to start your contributions.
You can find some impefect implementation in Qlib by
rg 'TODO|FIXME' qlib`如果您想成为 Qlib 的维护者之一以做出更多贡献(例如帮助合并 PR、分类问题),请通过电子邮件联系我们(qlib@microsoft.com)。 我们很高兴帮助您升级权限。
License
Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the right to use your contribution. For details, visit https://cla.opensource.microsoft.com.当您提交拉取请求时,CLA 机器人将自动确定您是否需要提供
CLA 并适当地装饰 PR(例如,状态检查、评论)。只需按照说明操作即可
由机器人提供。您只需使用我们的 CLA 在所有存储库中执行一次此操作。
本项目采用了Microsoft 开源行为准则.
欲了解更多信息,请参阅行为准则常见问题解答 or
contact opencode@microsoft.com如有任何其他问题或意见。
💡 精彩内容推荐
✍️ 楼主最新发布
- •
- •
- •
- •
- •
- •
🔗 您可能感兴趣
- •
- •
- •
- •
- •
- •
