使用 ONNX 模型识别手写数字的示例 - MetaTrader 5 专家

这MNIST数据库包含 60,000 张训练图像和 10,000 张测试图像。这些图像是通过“重新混合”一组原始的 NIST 20x20 像素黑白样本而创建的,这些样本又从美国人口普查局获得,并补充了从美国高中生采集的测试样本。将样本标准化为 28x28 像素大小并进行抗锯齿处理,从而引入灰度级别。
训练好的手写数字识别模型 mnist.onnx 从 Github 下载模型动物园(opset 8)。有兴趣的人可以下载并尝试其他模型,不包括具有 opset 1 的模型,最新的 ONNX 运行时不再支持该模型。令人惊讶的是,输出向量没有经过处理软最大激活函数,这在分类模型中很常见。嗯,这不是问题,因为我们可以自己轻松实现。
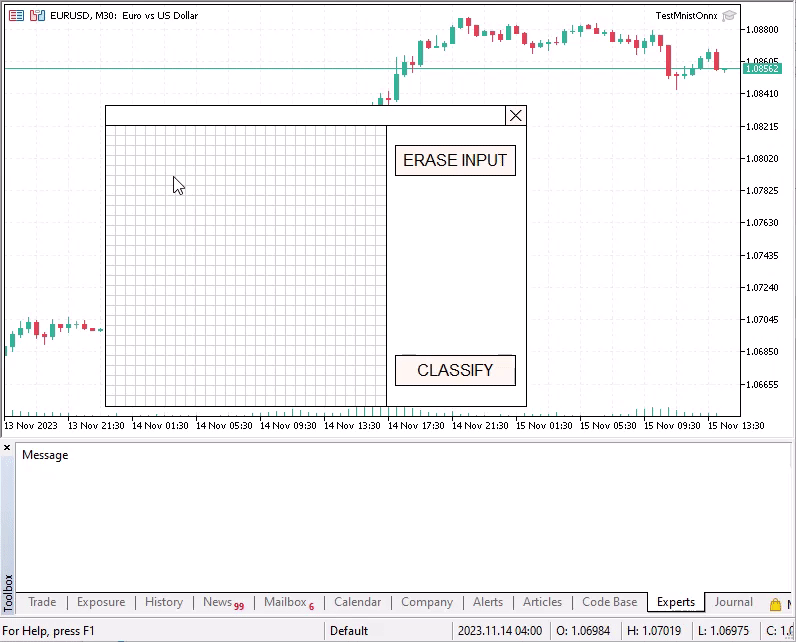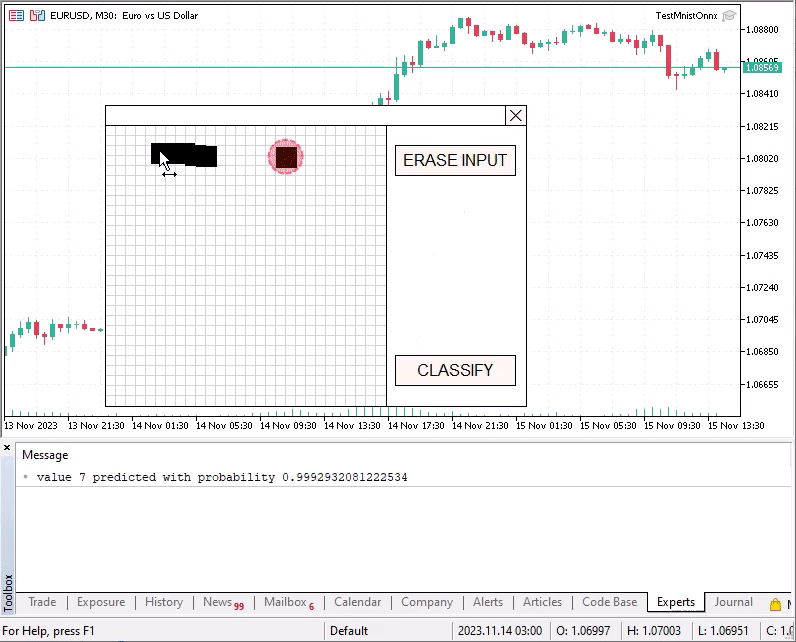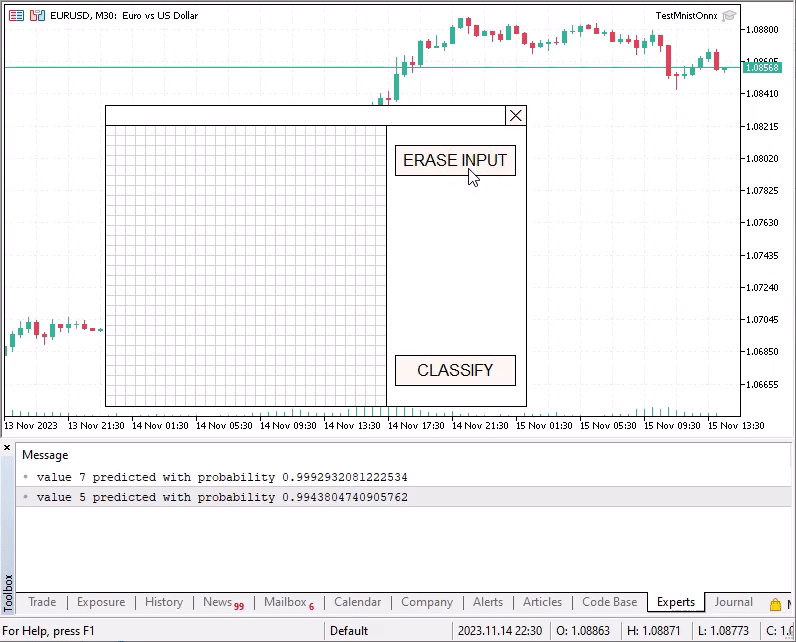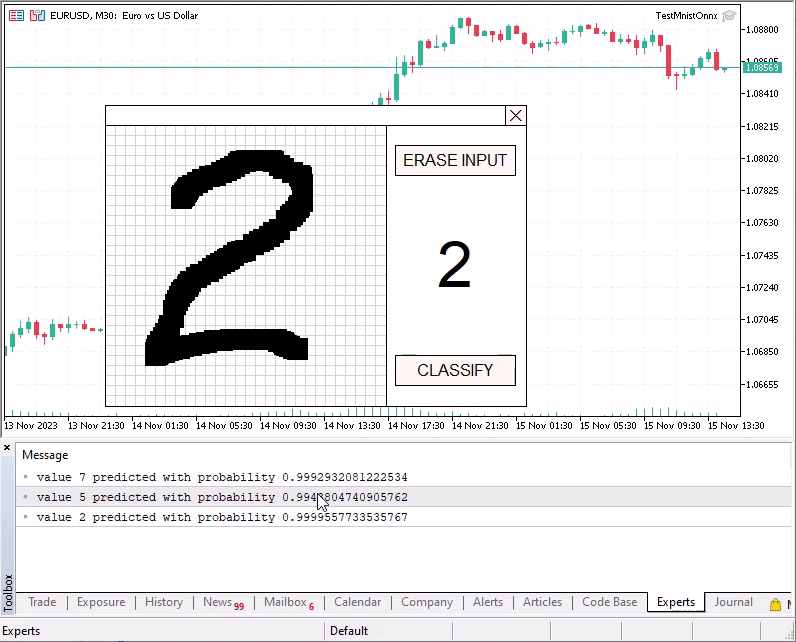
整数预测数(空白) { 静止的 矩阵f图像(28,28); 静止的 向量f结果(10); 准备矩阵(图像); 如果(!Onnx运行(外部模型,ONNX_DEFAULT,图像,结果)) { 打印(“Onnx运行错误 ”,获取最后一个错误()); 返回(-1); } 结果.激活(结果,AF_SOFTMAX); 整数预测=整数(结果.ArgMax()); 如果(结果[预测]<0.8) 打印(结果); 打印("值",预测,"以概率预测",结果[预测]); 返回(预测); }
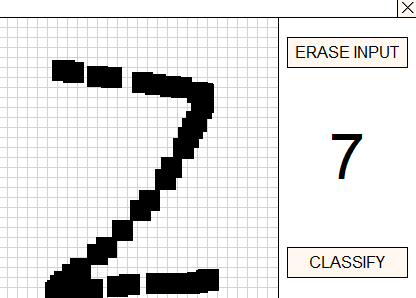
使用鼠标在特殊网格中绘制数字,按住鼠标左键。要识别绘制的数字,请按分类按钮。
如果所获得的已识别数字的概率小于 0.8,则将包含每个类别的概率的结果向量打印到日志中。例如,尝试对空的未填充输入字段进行分类。
[0.095331445,0.10048489,0.10673151,0.10274081,0.087865397,0.11471312,0.094342403,0.094900772,0.10847695,0.09441267] 价值5以概率预测0.11471312493085861由于某种原因,数字九 (9) 的识别准确度明显较低。向左倾斜的数字识别更准确。
附件下载
📎 testmnistonnx.mq5 (8.36 KB)
📎 mnist.onnx (25.83 KB)
Source: MQL5 #47225
💡 精彩内容推荐
✍️ 楼主最新发布
- •
- •
- •
- •
- •
- •
🔗 您可能感兴趣
- •
- •
- •
- •
- •
- •
🔐
请登录后参与评论
注册满12小时后评论,即可解锁附件下载
立即登录

